
Supervision Nagios
Nagios qu’est-ce que c’est ?
Nagios est une solution pour superviser une infrastructure, voici un peut son histoire :
- en 1996, Ethan Galstad crée une petite application (sous MS-DOS !) pour effectuer des ping sur des serveurs. Le cœur de l’architecture applicative de Nagios est né ;
- deux ans plus tard, Ethan migre son application sous Linux. Et en 1999, il décide de la rendre disponible sous le nom de NetSaint, en estimant que cette application open source intéresserait probablement une douzaine de personnes ;
- mais comme souvent dans ces cas-là, il existait déjà une marque portant ce nom, alors Ethan a simplement renommé son application en utilisant un processus très à la mode chez les concepteurs à l’époque : l’acronyme récursif. Ainsi, NAGIOS peut être interprété comme « Nagios Ain’t Gonna Insist On Sainthood » ;
- en 2007 est créée Nagios Enterprises LLC, dans le but de structurer le travail et les prestations autour de Nagios ;
- en 2009, la douzaine d’utilisateurs s’est transformée en quelques 600 000 téléchargements ;
- en 2016, Nagios dépasse les 7 500 000 téléchargements directs sur la plateforme SourceForge.
Pour ce TP j’ai conservé l’environnement du TP « Apache2 et HAProxy ».
A présent nous allons commencer l’installation :
Sudo apt update && sudo apt upgrade
Ensuite nous allons installer quelques dépendances qui sont nécessaires au bon fonctionnement et à l’utilisation de Nagios :
sudo apt install -y apache2 php libapache2-mod-php build-essential libgd-dev unzip
Puis la création de l’utilisateur Nagios :
sudo useradd nagios
sudo groupadd nagcmd
sudo usermod -a -G nagcmd nagios
sudo usermod -a -G nagcmd www-data
nagios sera l’utilisateur qui exécute le service
nagcmd permet la gestion des commandes via l’interface web (CGI)
On ajoute aussi www-data (utilisateur Apache) au groupe nagcmd pour accès web
Passons à présent au téléchargement de Nagios : (pensez à vérifier les versions)
Installation de Nagios Core
Passons maintenant au téléchargement et à l’installation de Nagios (veillez à vérifier la version la plus récente) :
cd /tmp
wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.5.9.tar.gz
tar zxvf nagios-4.5.9.tar.gz
cd nagios-4.5.9
./configure --with-command-group=nagcmd
make all
sudo make install
sudo make install-init
sudo make install-commandmode
sudo make install-config
sudo make install-webconf
Configuration de l’accès web
On configure l’accès à l’interface web de Nagios en créant un utilisateur nagiosadmin protégé par mot de passe :
sudo htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
Activation du module CGI d’Apache
Ce module permet à Apache d’interpréter les scripts .cgi, nécessaires pour l’interface web de Nagios :
sudo a2enmod cgi
sudo systemctl restart apache2
Démarrage et activation de Nagios
Lancez Nagios et activez-le au démarrage du système :
sudo systemctl start nagios
sudo systemctl status nagios
sudo systemctl enable nagios
Vérification de la configuration
Avant d’aller plus loin, on vérifie que le fichier de configuration principal de Nagios ne contient pas d’erreurs :
sudo /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
PARFAIT !
On teste l’accès à l’interface graphique dans un navigateur :
On se log et :
Installation des plugins Nagios
Une fois Nagios installé, passons à l’installation des plugins, nécessaires pour surveiller les services (HTTP, ping, SSH, etc.).
(⚠️ Pensez à vérifier la dernière version sur le site officiel)
cd /tmp
wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
tar zxvf nagios-plugins-2.3.3.tar.gz
cd nagios-plugins-2.3.3
./configure --with-nagios-user=nagios --with-nagios-group=nagios
make
sudo make install
Une fois l’installation terminée, on redémarre Nagios pour qu’il prenne en compte les nouveaux plugins :
sudo systemctl restart nagiosA présent nous allons installer les NRPE sur les serveurs que l’on souhaite surveiller :
Qu’est-ce que NRPE dans Nagios ?
NRPE (Nagios Remote Plugin Executor) est un agent Nagios qui permet au serveur Nagios d’exécuter des plugins à distance sur d’autres machines Linux.
NRPE permet à Nagios d’interroger des clients distants (les serveurs surveillés) pour connaître par exemple :
- La charge CPU
- L’espace disque
- L’état de certains services
Sur les clients à surveiller (nos deux apache2 et notre haproxy)
- Mettre à jour les paquets et installer NRPE + plugins :
sudo apt update
sudo apt install -y nagios-nrpe-server nagios-plugins
- Configurer NRPE :
sudo subl /etc/nagios/nrpe.cfg
À vérifier/modifier :
Cherchez la ligne suivante et ajoutez l’IP de votre serveur Nagios :
allowed_hosts=127.0.0.1,IP_DU_SERVEUR_NAGIOS
➡️ Exemple :
allowed_hosts=127.0.0.1,192.168.2.11
- Redémarrer le service NRPE :
sudo systemctl restart nagios-nrpe-server
Sur le serveur Nagios
- Installer les dépendances nécessaires pour compiler NRPE :
sudo apt update
sudo apt install -y autoconf gcc libmcrypt-dev make libssl-dev libtool
- Télécharger et compiler uniquement le plugin
check_nrpe:
cd /tmp
wget https://github.com/NagiosEnterprises/nrpe/archive/refs/tags/nrpe-4.1.0.tar.gz
tar -xzf nrpe-4.1.0.tar.gz
cd nrpe-nrpe-4.1.0/
./configure --enable-command-args
make check_nrpe
sudo cp src/check_nrpe /usr/local/nagios/libexec/
- Tester la communication avec le client :
/usr/local/nagios/libexec/check_nrpe -H IP_DU_CLIENT
Si tout fonctionne, vous devriez voir un message comme :

Nous allons nous rendre dans le répertoire de fichiers objets de Nagios.
Pour ma part, c’est /usr/local/nigios/etc/objects/.
Nous allons créer un fichier hosts.cfg pour déclarer les hosts et les services.
Vous pouvez créer un fichier host.cfg pour déclarer les host et un fichier services.cfg pour les services ou compiler les deux sur le fichier host. J’ai choisi de tous mettre dans le fichier host.
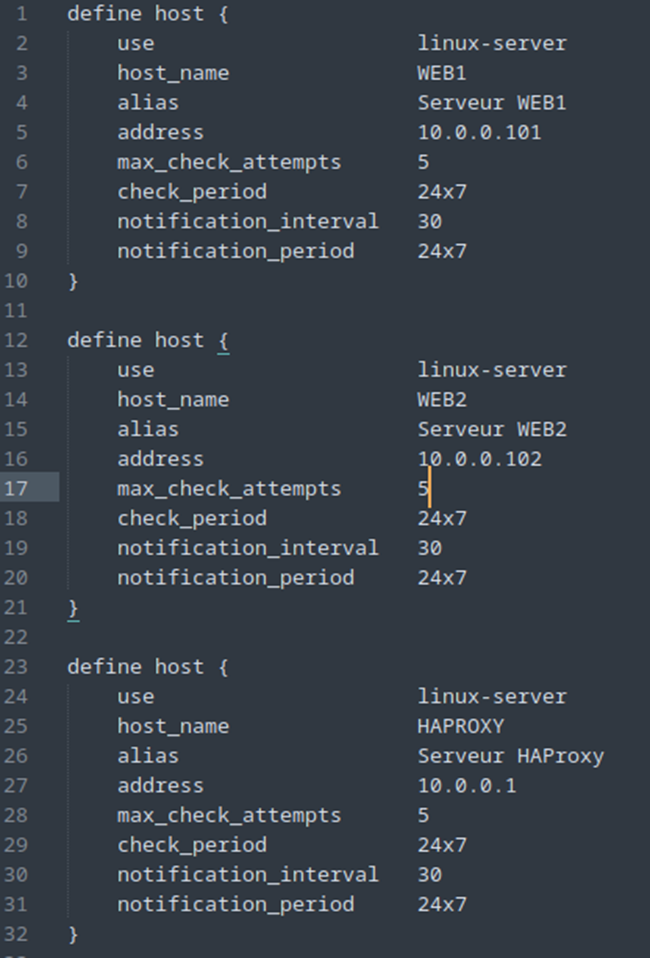
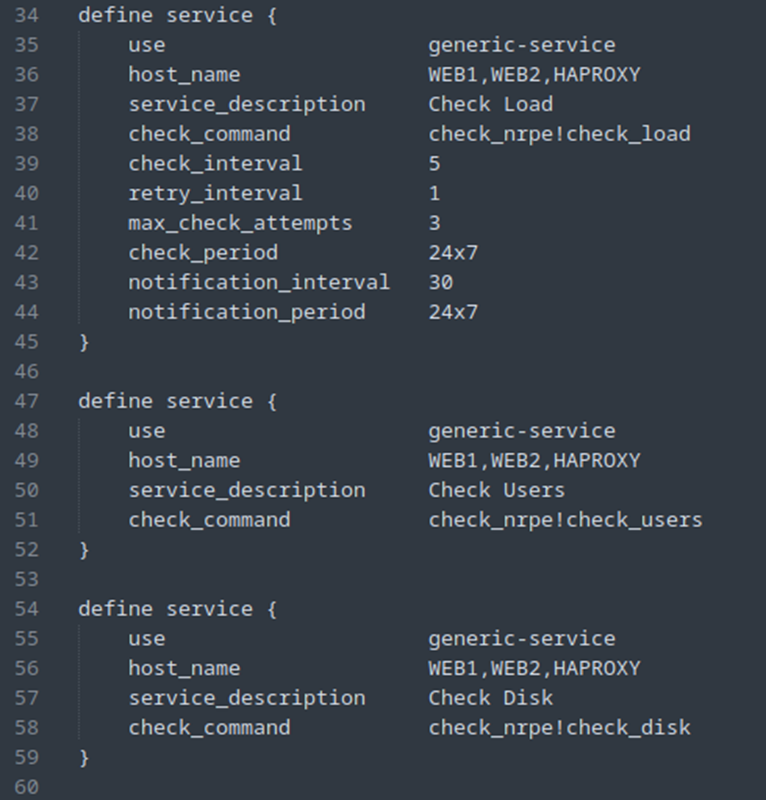
Description configuration d’un host :
- define host { … }
C’est la déclaration d’un objet de type host (hôte). - use linux-server
Utilise un template appelélinux-serverqui contient des paramètres par défaut (ex : commandes de vérification, options de notification). Cela évite de tout réécrire à chaque fois. - host_name web1
Le nom unique de l’hôte dans Nagios. C’est ce nom que tu utiliseras pour lier des services, des notifications, etc. - alias Serveur Web 1
Un nom plus lisible ou descriptif, utilisé dans l’interface web pour identifier l’hôte. - address 10.0.0.101
L’adresse IP ou le nom de domaine que Nagios va surveiller pour cet hôte. - max_check_attempts 5
Le nombre maximal de tentatives de vérification avant de considérer que l’hôte est down (en panne). - check_period 24×7
La période durant laquelle les vérifications sont autorisées (ex : 24×7 signifie toute la journée, tous les jours). - notification_interval 30
Intervalle (en minutes) entre deux notifications en cas de problème persistant. - notification_period 24×7
Période durant laquelle les notifications peuvent être envoyées.
Nous reviendrons sur les services plus tard.
Point important il faut bien vérifier le fichier de configuration nagios.cfg et ajouter si besoin la ligne :
Pour ma part il ce situe : /usr/local/nagios/etc/nagios.cfg
cfg_file=/usr/local/nagios/etc/objects/host.cfg
Cela va lui permettre de savoir où récupérer les informations que nous venons de lui inscrire dans le fichier host.
A partir de là nous avons sur l’interface web Nagios, dans l’onglet « host » nos host et nos quelques services de base:
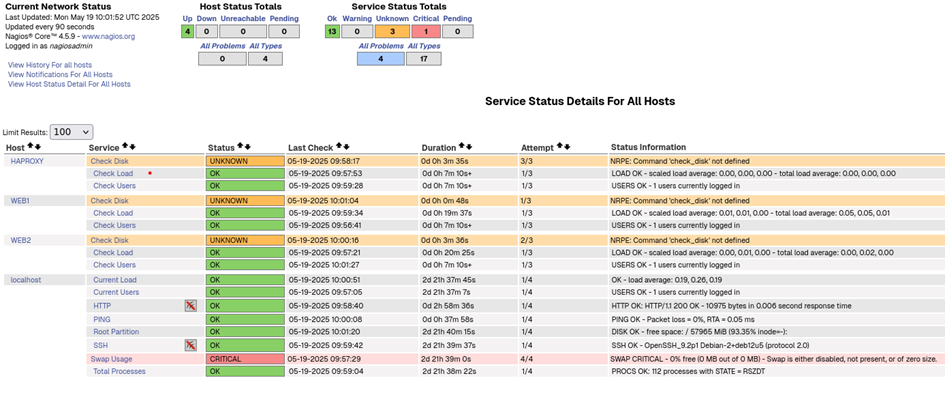
On constate que la commande check-disk ne fonctionne pas. Pourquoi ?
Parce que sur nos clients, le fichier nrpe.cfg n’est pas tout à fait correct pour ce check.
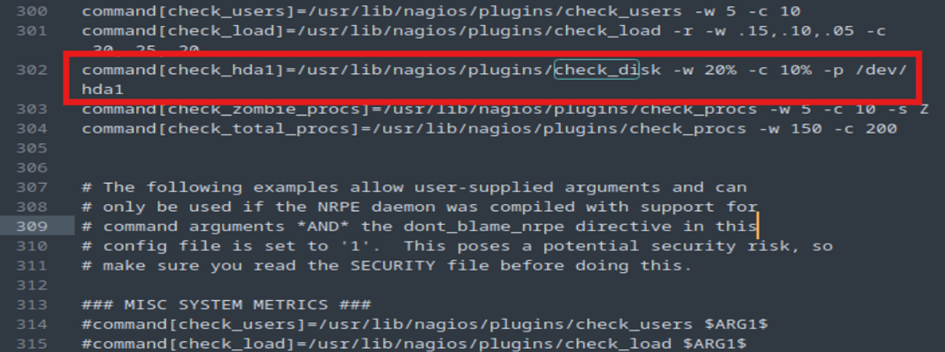
La partition ciblée n’est pas correcte.
À partir de là, nous avons plusieurs possibilités :
- La première est de changer la cible de la commande
check_disken mettant simplement comme argument la racine « / ». - La deuxième est de cibler la bonne partition en la vérifiant sur notre machine cliente.
Pour la démonstration, j’ai ajouté une ligne pour chacune des possibilités .
Attention, pour cela, il faut ajouter le deuxième service dans le fichier host de notre serveur Nagios, comme indiqué ci-dessous :
Fichier host.cfg sur le serveur Nagios :
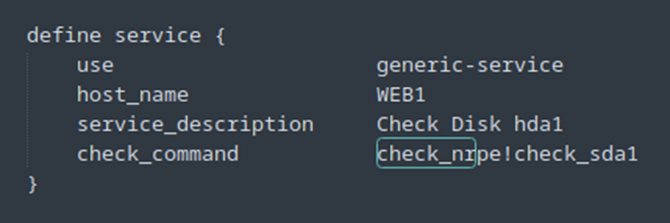
J’ai préalablement regardé les partitions de ma VM Web1.
Fichier « nrpe.cfg » su le client Web1 :

On redémarre les services (serveur-nrpe sur les clients et Nagios sur le serveur Nagios) et vous pouvez retrouver la donnée sur l’interface web de Nagios :
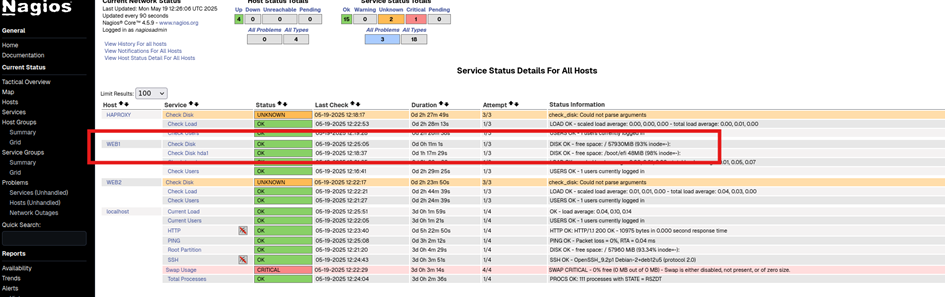
Nous retrouvons pour l’host Web1 nos deux nouvelles mesures.
Ensuite j’ai modifié la commande check_disk sur chaque fichier nrpe de mes host.
Comme vous pouvez le constater, nous avons configuré les lignes de manière à obtenir un warning à 20 % de mémoire restante et un critical à 10 % de mémoire restante (-w 20% et -c 10%).
On peut constater que l’usage du swap est critique, ce qui est normal puisque je n’ai pas configuré de mémoire swap sur cette VM (le swap correspond à une partie du disque dur utilisée comme mémoire RAM).
On remarque aussi un problème avec SSH, qui est considéré comme désactivé.
Pour vérifier le statut de SSH, on utilise la commande :
sudo systemctl status ssh
Sur ma machine, il était désactivé.
Pour l’activer et le lancer au démarrage, on exécute :
sudo systemctl enable ssh
sudo systemctl start ssh
Puis je vais tester le check_ssh avec la commande :
/usr/local/nagios/libexec/check_ssh localhost

On voit aussi que les notifications sont désactivées pour les services HTTP et SSH.
Nous allons les activer très simplement via l’interface web :
Il suffit de cliquer sur le service.

Puis on clique sur « Enable notification for this service » (sur la capture d’écran, c’est « disable » car je viens de la réaliser, mais ce sera au même endroit).
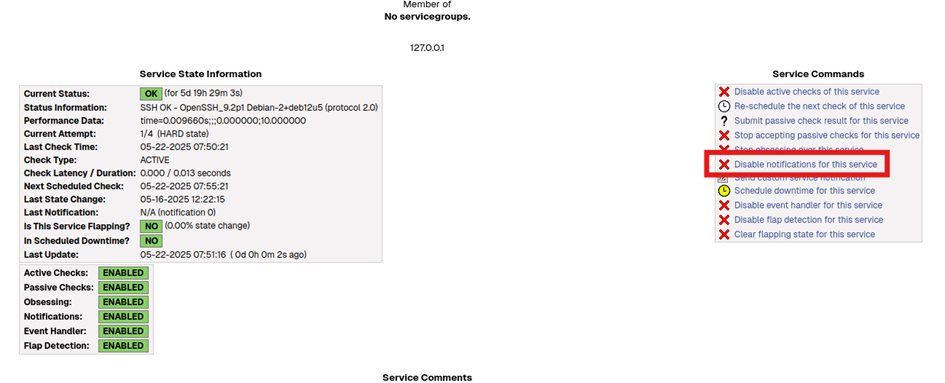
Les services :
À présent, nous allons ajouter quelques services à surveiller.
Dans un premier temps, le ping ou ICMP.
Pour commencer, sur le serveur Nagios il faut vérifier si le service existe dans le fichier commands.cfg.
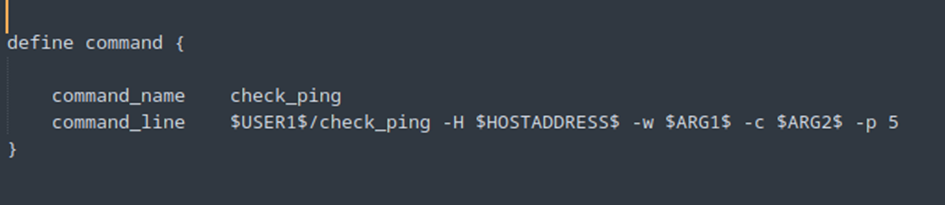
Ensuite, on ajoute le service dans host.cfg ou service.cfg, selon votre configuration.
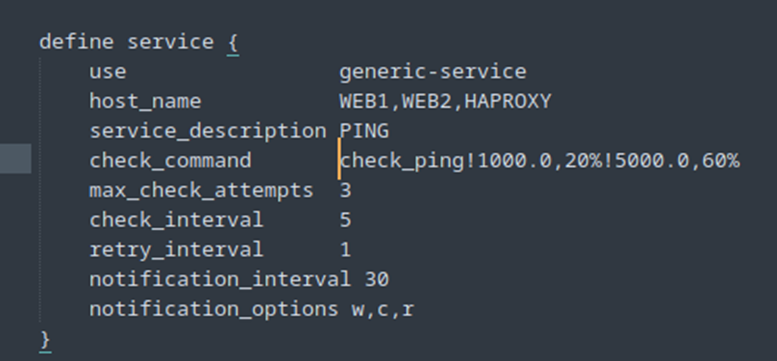
· -w 1000 : avertissement si la latence dépasse 1000 ms 0.20% seul de latence
· -c 5000 : critique si la latence dépasse 5000 ms 0.60% perte de paquet
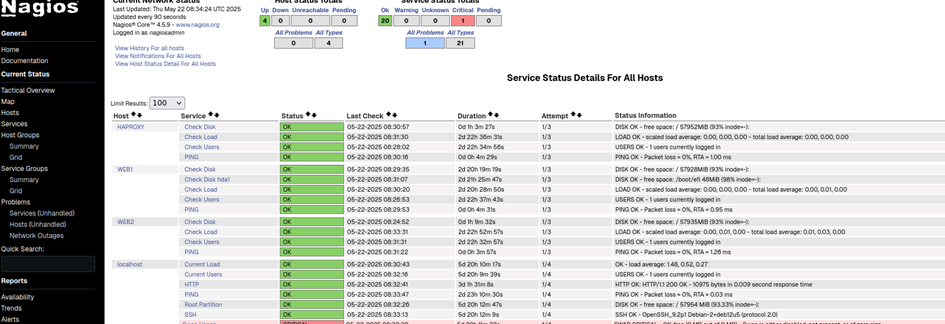
Ce qui nous donne :
On enchaîne avec un service important pour contrôler l’état des serveurs Apache2 et HAProxy.
Dans un premier temps, nous allons modifier le fichier nrpe.cfg sur les serveurs web pour ajouter une commande permettant de surveiller le processus Apache2 :

De même sur le fichier nrpe.cfg sur le serveur HAProxy pour traquer le processus de ce dernier :

A présent nous allons configurer le fichier host.cfg sur Nagios pour ajouter les deux services :
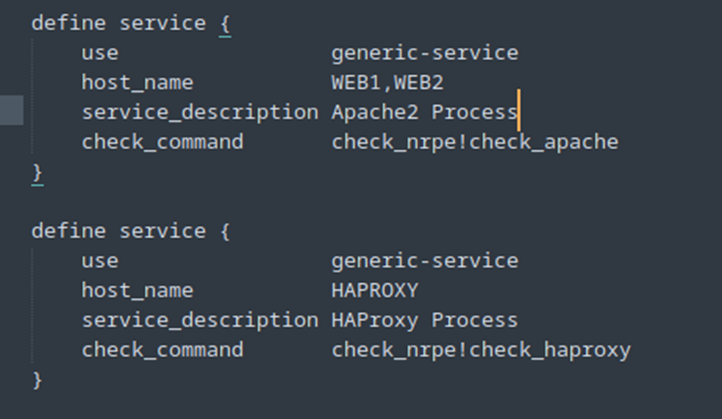
Tout fonctionne :
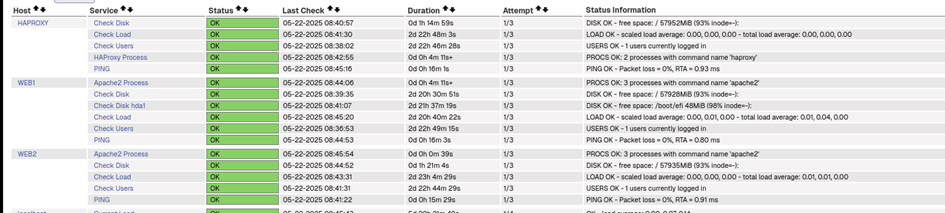
Nous allons stopper un serveur apache2 (Web1) pour voir si le contrôle fonctionne bien :
Sudo systemctl stop apache2
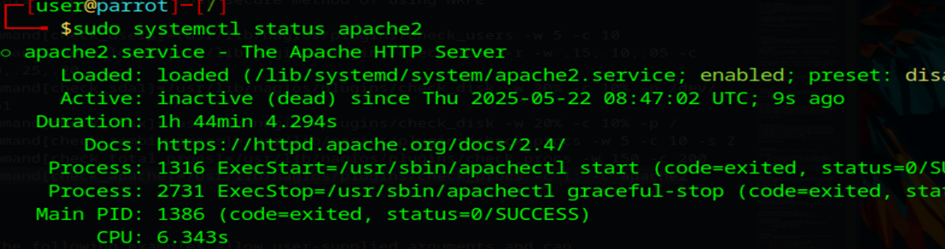
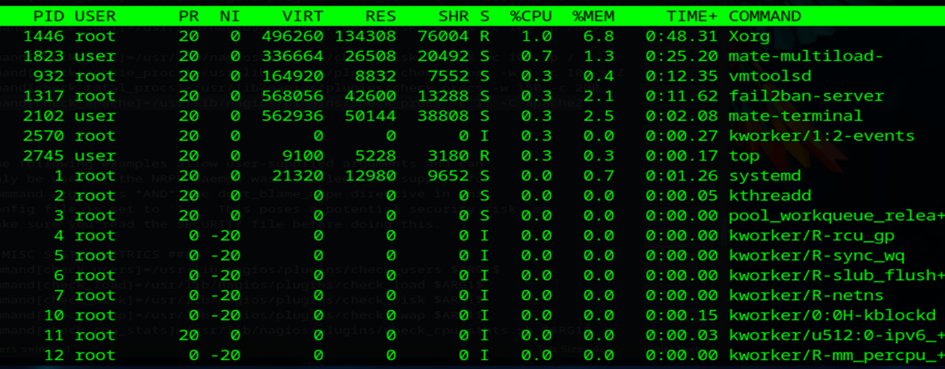
On regarde si le processus c’est éteint : (logiquement oui)
top
J’ai arrêté Apache2, donc le processus n’est plus actif sur le serveur. Nous devrions avoir un état critique sur Nagios.
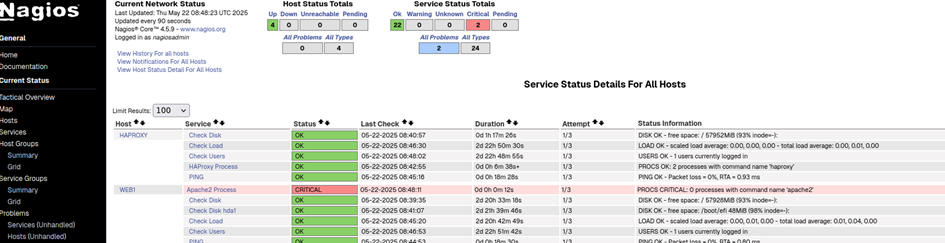
C’est parfait !
On va finir avec la configuration d’un service pour contrôler le processeur (CPU) et la RAM.
Pour le processeur, c’est assez simple : nous allons simplement ajouter une commande dans le fichier nrpe.cfg des clients.

Les seuils de surveillance dépendent du nombre de cœurs du processeur de la machine à contrôler. Dans mon cas, j’ai 4 cœurs, et j’ai configuré une vérification basée sur la charge CPU sur les 1, 5 et 15 dernières minutes.
Concrètement, si la charge moyenne dépasse 3, l’état sera en warning, et si elle dépasse 4, ce sera en critical.
Pour le fichier commands.cfg, aucune modification n’est nécessaire car la vérification utilise déjà le plugin check_nrpe.
En revanche, dans le fichier host.cfg, il faudra ajouter ce nouveau service de contrôle de la charge CPU.
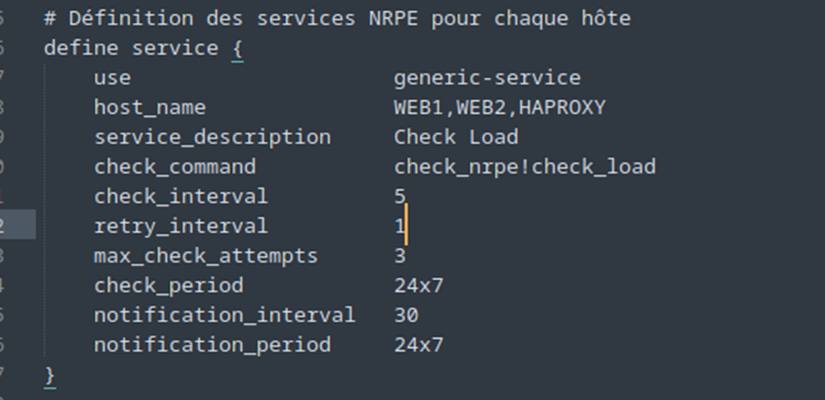
Et pour que le serveur Nagios puisse se contrôler lui-même, on va ajouter le service dans le fichier localhost.cfg. Attention, il s’agit bien du fichier localhost.cfg de Nagios, situé dans : /usr/local/nagios/etc/objects/.
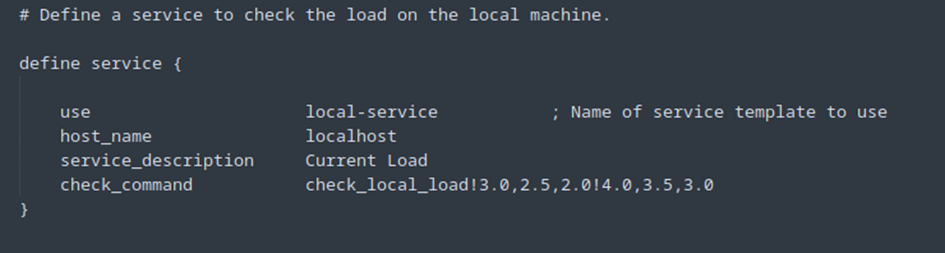
À présent, pour la RAM, c’est un peu plus compliqué car nous n’avons pas de plugin check_ram prêt à l’emploi. Il va donc falloir créer un petit script nous-mêmes.
Nous allons procéder étape par étape :
On commence par créer ce script sur les clients et l’enregistrer dans le répertoire des plugins de nos hosts.
sudo subl /usr/lib/nagios/plugins/check_em.sh
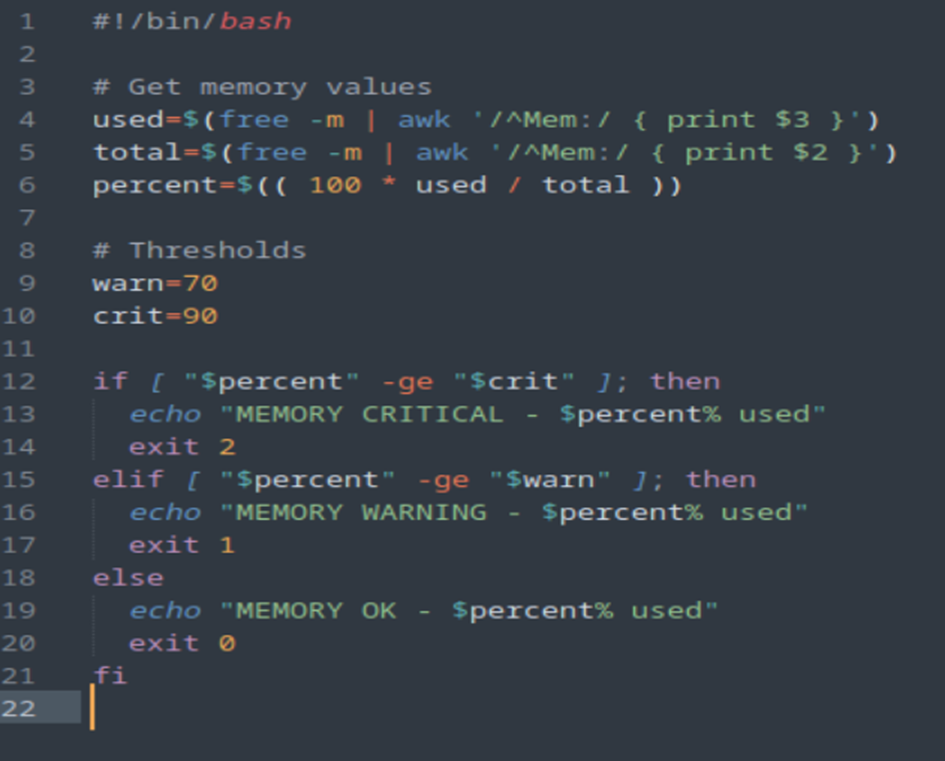
Ensuite, nous allons donner les droits d’exécution à ce script :
sudo chmod +x /usr/lib/nagios/plugins/check_mem.sh
Pour finir, sur les clients, nous allons ajouter la commande NRPE dans le fichier nrpe.cfg :

Et bien sûr, on redémarre le service NRPE.
sudo systemctl restart nagios-nrpe-server
On passe ensuite sur le serveur Nagios.
On va commencer par créer les deux commandes Nagios sur le fichier comandes.cfg :
- Première commande pour NRPE vers les clients :

- La deuxième commande permettra d’exécuter le script en local :

Comme vous l’aurez compris, nous allons maintenant créer le script sur le serveur Nagios, dans le répertoire où se trouvent ses plugins (attention, ce n’est pas le même que pour les clients).
sudo subl /usr/local/nagios/libexec/check_mem.sh
Le script sera le même que celui utilisé sur les clients.
Ensuite, nous devons ajouter le service dans le fichier host.cfg (ou service.cfg) pour les clients :
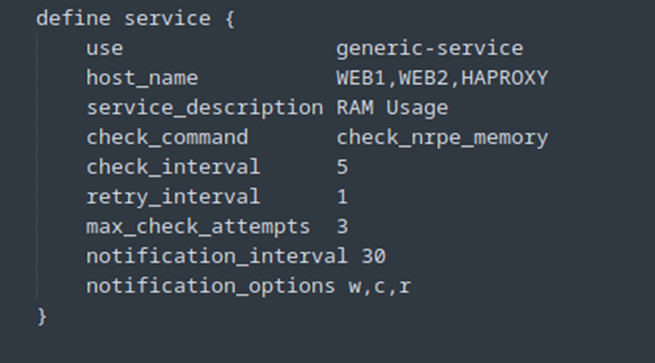
Pour finir il nous faut ajouter le service pour le serveur Nagios et donc l’ajouter dans le fichier localhost.cfg.
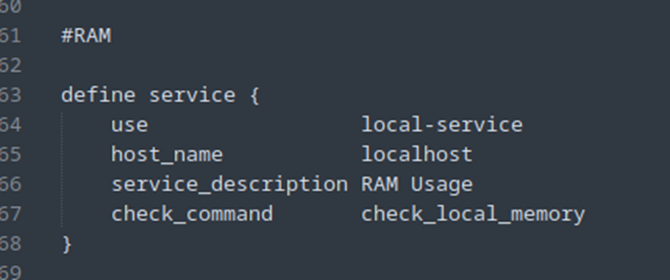
On restart Nagios et on devrait avoir nos nouveaux services :
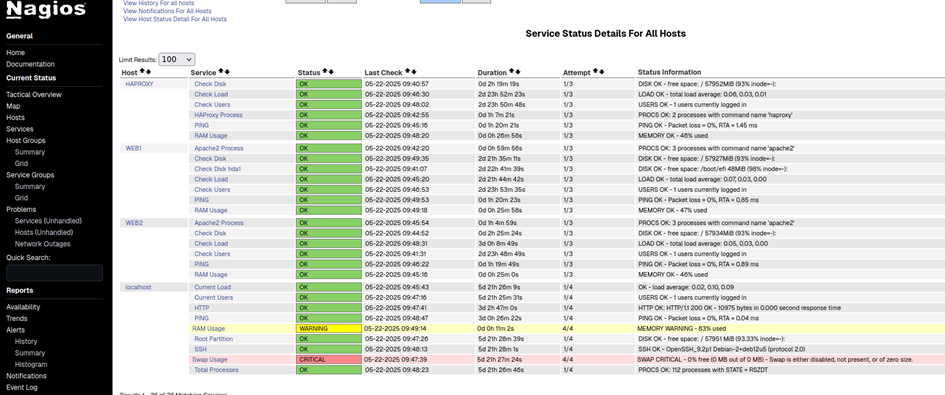
Et voilà, nous commençons à avoir un tableau de bord intéressant qui fonctionne parfaitement. On peut ainsi constater que la RAM du serveur Nagios est déjà bien sollicitée.
Petit point sur les fichiers de configuration :
🔧Client et serveur Nagios :
- Plugins :
Ce sont de petits scripts (souvent en bash, Perl, ou C) qui permettent d’exécuter différentes commandes de surveillance (CPU, RAM, disque, etc.).
💻 Côté client (machine surveillée) :
nrpe.cfg:
Fichier de configuration du service NRPE.
Il contient les commandes autorisées que le serveur Nagios peut exécuter à distance viacheck_nrpe.
NRPE permet de faire le lien entre le serveur Nagios et le client, en acceptant des requêtes de contrôle.
📡 Côté serveur Nagios :
hosts.cfg:
Sert à déclarer les machines surveillées (hôtes), avec leur nom, IP, et éventuellement des groupes ou modèles.
On peut aussi y définir des services associés (même si on préfère parfois les séparer dans unservices.cfg).services.cfg:
Contient la configuration des services à surveiller sur les hôtes : ping, CPU, RAM, Apache, etc.
Chaque service est lié à une commande de vérification.commands.cfg:
Définit les commandes Nagios : c’est la structure qui indique quelle commande exécuter et avec quels arguments.
Exemple :check_command check_ping!100,20!500,60.nagios.cfg:
Fichier de configuration principale de Nagios.
Il indique quels fichiers inclure (cfg_file) pour charger les hôtes, services, commandes, etc.localhost.cfg:
Contient la configuration des services à surveiller sur le serveur Nagios lui-même (localhost).resource.cfg:
Fichier qui contient des variables personnalisées (comme$USER1$,$USER2$, etc.).
On y stocke généralement des chemins (ex:/usr/lib/nagios/plugins) ou des identifiants sensibles.
Nous allons terminer en configurant l’envoi d’un mail en cas d’alerte warning ou critical.
Pour cela, nous aurons besoin de msmtp, qui permettra d’envoyer les mails via SMTP, ainsi que de sendmail (émulé par msmtp), utilisé par Nagios pour l’envoi des notifications par mail.
Pour bien comprendre le processus voici quelques explications :
1. 🖥️ Nagios
Nagios est un logiciel de supervision.
Quand un problème est détecté (ex. : un serveur ne répond plus, un service est en erreur), Nagios ne sait pas envoyer un mail lui-même.
Il exécute une commande externe (définie dans sa configuration) pour le faire.
👉 Cette commande appelle un programme capable d’envoyer un e-mail, en général sendmail.
2. 📤 sendmail (interface standard)
Historiquement, sendmail est un programme Unix standard utilisé par des logiciels pour envoyer du courrier électronique.
Nagios (comme beaucoup d’autres outils) envoie un mail en appelant un binaire nommé /usr/sbin/sendmail avec des arguments, comme :
/usr/sbin/sendmail -tCe programme prend le contenu du mail (envoyé via stdin) et l’expédie.
🧩 Problème :
Le vrai sendmail est un gros serveur de mail (comme Postfix ou Exim), lourd à configurer.
Mais Nagios a juste besoin d’un outil simple pour expédier un e-mail via SMTP.
3. ✨ msmtp : un client SMTP simple
msmtp est un programme léger qui peut envoyer un mail via un serveur SMTP (comme Gmail, OVH, etc.).
Il peut être configuré pour se comporter comme le programme sendmail.
C’est ce qu’on appelle ici « émuler » sendmail.
⚙️ Que signifie « émuler sendmail » ?
Imiter le comportement d’un autre programme pour permettre une compatibilité.
Donc :
msmtpn’est passendmail, mais- il fournit un binaire qui a le même nom, les mêmes arguments, et le même comportement d’entrée (
stdin) quesendmail.
Cela permet à des programmes comme Nagios de croire qu’ils utilisent sendmail, alors qu’en réalité, c’est msmtp derrière.
👉 msmtp « émule » sendmail pour que Nagios puisse l’utiliser sans adaptation.
ACTION :
On va donc commencer par installer msmtp et mailutils :
sudo apt update
sudo apt install msmtp msmtp-mta mailutils
· msmtp-mta fournit la commande sendmail, qui pointe vers msmtp.
· mailutils fournit la commande mail, utilisée par Nagios.
Ensuite nous allons créer et configurer msmtp :
Sudo subl /etc/msmtprc
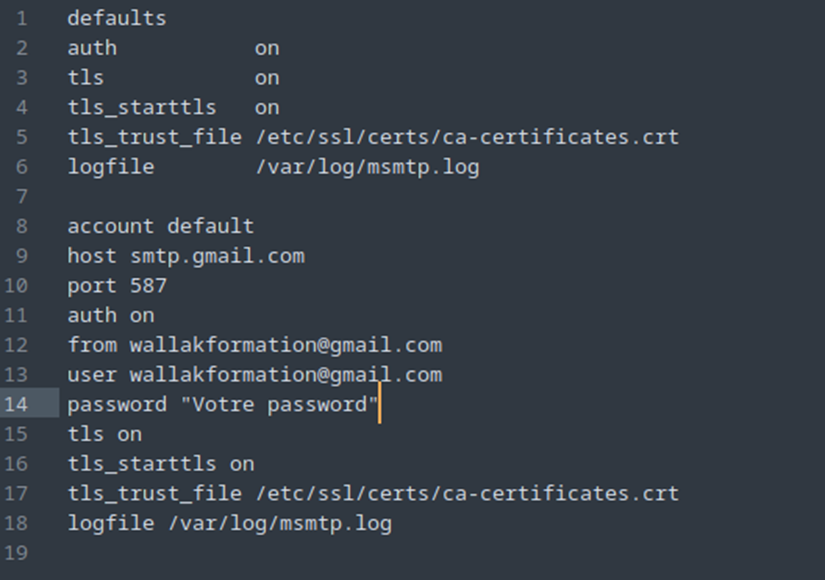
Pour ce fichier, soit vous mettez votre mot de passe de l’adresse mail Google, soit, si vous avez activé la double authentification, vous devrez générer un mot de passe d’application. Vous pouvez le faire via ce lien :
https://myaccount.google.com/apppasswords
Ensuite, donnez les droits de lecture à Nagios pour le fichier msmtprc :
sudo chown root:nagios /etc/msmtprc
sudo chmod 640 /etc/msmtprc
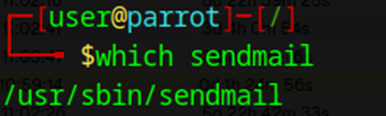
Puis, tapez la commande suivante pour trouver la commande sendmail :
which sendmail
Elle devrait retourner :
Si ce n’est pas le cas, vérifiez votre fichier ~/.bashrc pour ajouter /usr/sbin à votre PATH.
Ajoutez cette ligne dans le fichier :
export PATH=$PATH:/usr/sbin
Puis rechargez votre terminal avec la commande :
source ~/.bashrc
À présent, testez la commande :
bashCopierModifierecho "Test email avec from défini" | /usr/sbin/sendmail -v « votre_adresse_mail »
Cela devrait fonctionner.
J’ai bien reçu le mail.
Il ne nous reste plus qu’à configurer Nagios.
Comme d’habitude, nous allons commencer par ajouter la commande. Pour cela, rendez-vous dans le fichier commands.cfg où nous allons ajouter la configuration suivante :
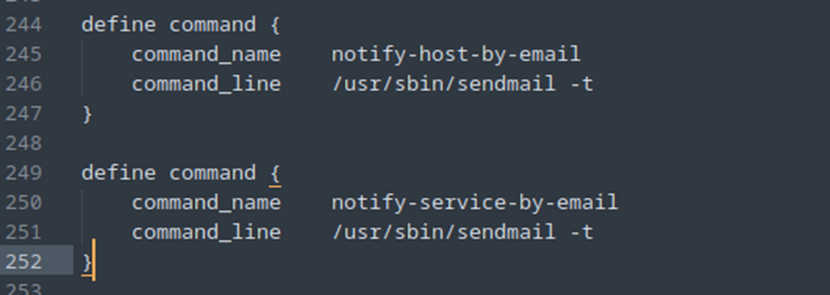
Une alerte pour l’host et une autre pour les services.
Nous allons à présent créer un contact pour Nagios.
Soit vous disposez déjà d’un fichier contacts.cfg, soit il vous faudra le créer, par exemple dans /usr/local/nagios/etc/objects/contacts.cfg (pour ma part).
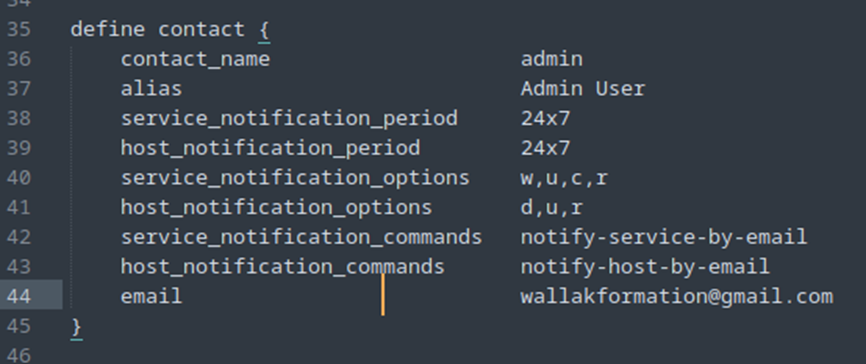
Puis on restart Nagios.
Comme ma RAM sur Nagios est déjà en warning après le restart je devrais recevoir un mail d’alerte :
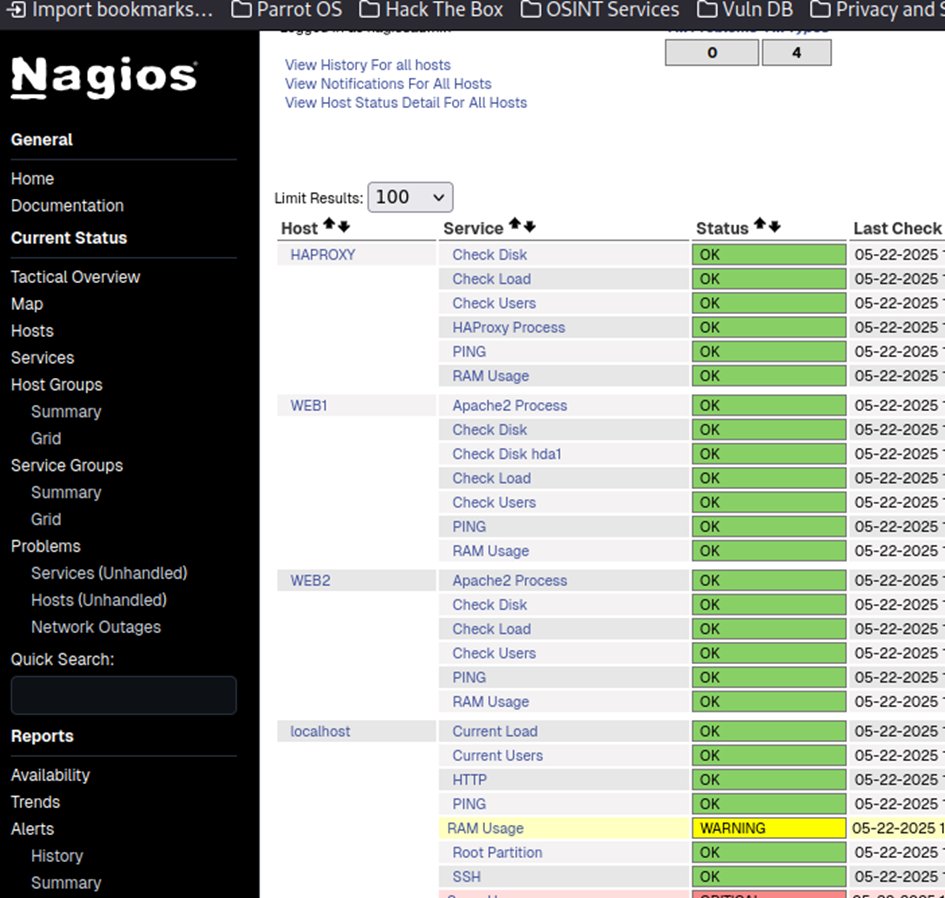
Et effectivement voici ce que j’ai reçu :
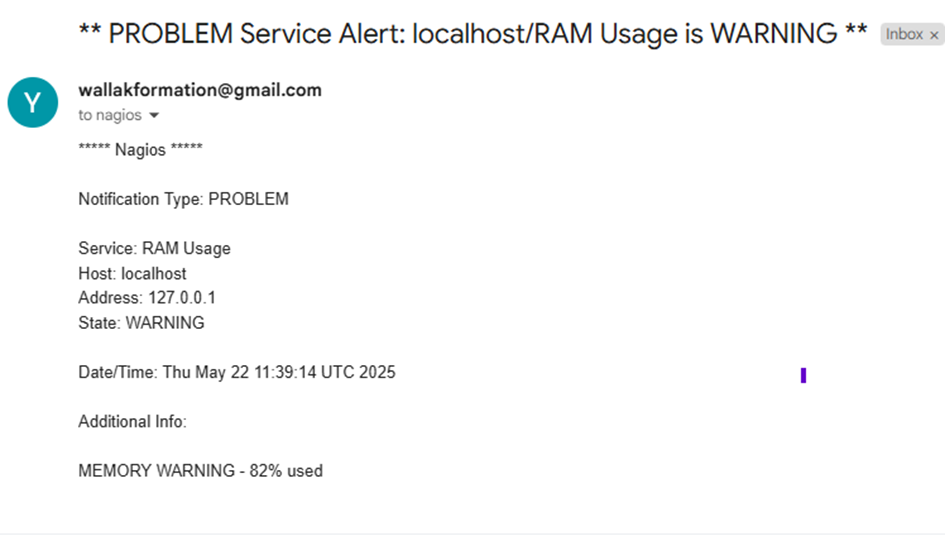
L’alerte mail fonctionne parfaitement.